Category: Groovy, Grails and GORM
[Grails] toString() method on domain class with id in output
Groovy has a cool annotation @ToString.
But I found strange behavior when trying to include id field to output of toString().
For example we have some domain class that marked with @ToString:
@ToString(includeNames = true, includeFields = true, includes = ['id'])
class User {
...
}
def user = new User()
user.id = 1 // id can't be bonded as a param of constructor, that's why we should set it directly
// Let's test generated toString()!
assert == 'User(id:1)' // assert fails!
But this assertion will fail: toString() skips id field. Maybe it happens because of id field is not declared explicitly in User class. It added implicitly by Grails.
I found workaround — just declare id field explicitly:
@ToString(includeNames = true, includeFields = true, includes = ['id'])
class User {
Long id
...
}
def user = new User()
user.id = 1
assert == 'User(id:1)' // assert successful 🙂
I dont know is this a bug or feature, but hope this workaround will help you.
[Grails] Параметры пейджинации как модель и простая фильтрация
Допустим есть простой доменный класс:
class User {
String email
String name
Date dateCreated
}
Сгенерируем контроллер, и посмотрим на list() action который выгребает из БД всех пользователей.
class UserController {
...
def list() {
respond User.list(), model:[userInstanceCount: User.count()]
}
...
}
Посмотрим что получилось в броузере:
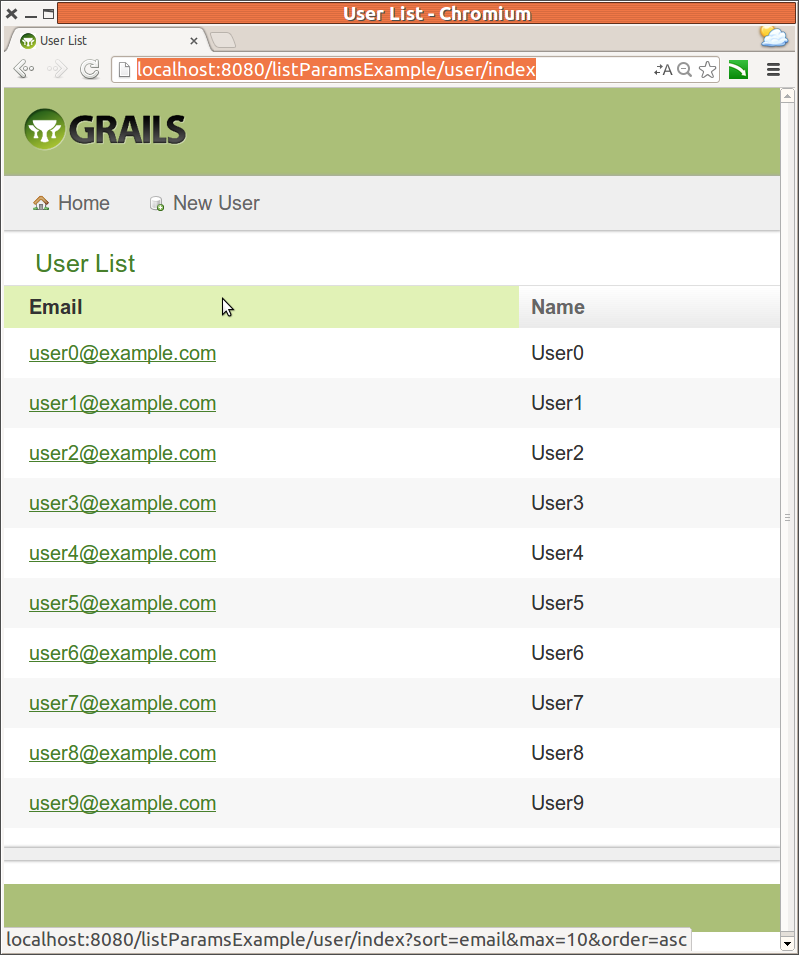
Что если мы хотим добавить пейджинацию? Очень просто, GORM метод list() имеет встроенную поддержку пейджинации. Например, у нас есть постраничный список пользователей. На каждой странице отображается по десять. Мы хотим выбрать третью страницу отсортированных по имени в восходящем порядке:
def books = User.list(offset: 20, max: 10, sort: 'name', order: 'asc')
offset — это сколько записей пропустить, max — сколько записей выбрать.
Тег добавляет пейджинатор который передаёт эти параметры в параметрах GET запроса. От туда мы их сразу передаём в list():
class UserController {
...
def list() {
respond User.list(params), model:[userInstanceCount: User.count()]
}
...
}
Тут могут возникнуть неприятности: хакер может задать очень большой max и такими большими запросами к БД положить сайт. Для этого нужно ограничивать max:
class UserController {
...
def list() {
params.max = Math.min(params.max ?: 10, 100)
respond User.list(params), model:[userInstanceCount: User.count()]
}
...
}
Хитрая конструкция Math.min(params.max ?: 10, 100) делает следующее:
Если max не задан, устанавливаем его по умолчанию в десять.
Если max задан больше 100, то он будет установлен в сто.
Простая защита для корректирования параметра max.
Если у вас контроллером уже много то эта строчка начинает повторятся. Мелочь, но коробит, DRY. Во вторых, на моём текущем проекте высокие требования по безопасности, и все параметры из запросов мы обязательно оборачиваем в Command object где их строго типизируем.
Так что даже на такую мелочь было решено написать простенький команд обжект:
@Validateable
class ListParams {
public static final int MAX_DEFAULT = 10
public static final int MAX_HIGH_LIMIT = 100
Integer max = MAX_DEFAULT
Integer offset
String sort
String order
static constraints = {
max(nullable: true, max: MAX_HIGH_LIMIT)
offset(nullable: true, min: 0)
sort(nullable: true, blank: false)
order(nullable: true, blank: false, inList: ['asc', 'desc'])
}
Map <String, Object> getParams() {
return [max: correctMax, offset: offset, sort: sort, order: order]
}
Integer getCorrectMax() {
return Math.min(max ?: MAX_DEFAULT, MAX_HIGH_LIMIT)
}
}
И принимаем его аргументом в list():
def index(ListParams listParams) {
respond User.list(listParams.params), model:[userInstanceCount: User.count()]
}
Стоило ли оно того? Наверное, да. Любая типизация и абстракция позволяет нам лучше протестировать и сделать более безопасное приложение.
Самое интересное начинается далее, когда вам начинают быть нужными фильтры. В таком случае можно создать простой класс UserListFilter отнаследованный от ListParams и добавляющий свои поля. Например на форме фильтра у нас есть ещё поле поиска по email, по имени и
@Validateable
class UserListFilter extends ListParams {
String email
String name
Date dateCreatedFrom
Date dateCreatedTo
}
И принимать сразу его через аргумент в контроллере, где Grails автоматически всё сконвертирует, сбиндит и провалидирует:
class UserController {
...
def index(UserListFilter filter) {
def criteria = User.where {
if (filter.email) {
email == filter.email
}
if (filter.name) {
name =~ '%' + filter.name + '%'
}
if (filter.dateCreatedFrom) {
dateCreated >= filter.dateCreatedFrom
}
if (filter.dateCreatedTo) {
dateCreated <= filter.dateCreatedTo
}
}
respond criteria.list(filter.params), model: [userInstanceCount: criteria.count(), filter: filter]
}
...
}
Результат:

Такой подход сократит вам много кода, и сделает его более безопасным и объектно ориентированным.
Пример демо проекта я выложил на гитхаб.
Software Environments
Программа может работать в разных условиях (environments), например у программиста на компьютере, где Windows и пару гибибайт оперативки, или на реальном «производственном» (production) сервере, с настоящей БД, с миллионом пользователей, мощным железом и под каким нибудь FreeBSD.
Соответсвенно на уровне конфигурации и кода нужно учитывать такие разные Environments.
Например если произошла ошибка то на компьютере программиста (development environment) мы вываливаем ему весь stacktrace, а вот на работающем сайте (production) мы пишем все ошибки только в логи, а перед пользователями извеняемся.
Так вот, какие чаще всего нужны Environments?
К сожалению я нигде в интернете не нашёл хорошего объяснения какие environments нужны и как их конфигурировать. Очень много и хорошо описано в документации к Grails но там описанные только самые базовые случаи.
Ещё немного описано в Википедии.
Поэтому постараюсь описать их все исходя из моего опыта.
Development, dev
Компьютер программиста
БД создаётся in-memory и каждый раз удаляется при выключении программы.
Пример конфигурации:
development {
dataSource {
url = 'jdbc:h2:mem:devDb' // Драйвер БД: H2, база в памяти, называние БД devDb
dbCreate = 'create' // Создать схему БД автоматически
loggingSql = true // Логировать SQL запросы
}
log4j = {
all 'grails.app' // Логируем всё из пакетов нашего приложения
root {
all 'stdout' // Выводим только в консоль
}
}
}
Здесь опция dbCreate = ‘create’ указывает что БД будет каждый раз снова создаваться снова.
прямо в оперативной памяти. При выходе из программы она будет уничтожатся.
More on dbCreate
Hibernate can automatically create the database tables required for your domain model. You have some control over when and how it does this through the dbCreate property, which can take these values:
create — Drops the existing schemaCreates the schema on startup, dropping existing tables, indexes, etc. first.
create-drop — Same as create, but also drops the tables when the application shuts down cleanly.
update — Creates missing tables and indexes, and updates the current schema without dropping any tables or data. Note that this can’t properly handle many schema changes like column renames (you’re left with the old column containing the existing data).
validate — Makes no changes to your database. Compares the configuration with the existing database schema and reports warnings.
Можно играться этими опциями.
Например если вы не хотите чтобы данные очищались, а просто обновилась схема то ставьте update и сохраняйте БД в файле.
Если у вас уже production БД то ставьте только validate а саму миграцию БД делайте с помощью SQL скриптов через инструменты DBMaintain или LiquidBase.
Test
Для прогона автоматических тестов.
Тут стоит отметить что тесты бывают:
- модульные (unit) — им не нужно никаких конфигураций Environments по определению
- интеграционные (integration, i11n) — вот для них обычно уже нужна БД а то и полностью стартовать сервер.
- функциональные (functional) — это когда имитируются действия пользователя, и проверяется что все кнопочки работают как должны.
Т.е. environment нужен для integration и functional и в идеале разный.
Production, prod
Настоящий сайт.
Тут стоит отметить что здесь нельзя хранить настоящие пароли от БД. Я бы рекомендовал просто указать имя DSN, например для JNDI или ODBC.
Логирование нужно настроить в файл и на email. А вот в консоль логировать бессмысленно.
production {
grails.serverURL = 'http://greenpay.com/'
portMapper.httpPort = 80
portMapper.httpsPort = 443
dataSource {
jndiName = "java:comp/env/myDataSource"
}
log4j = {
warn 'grails.app'
root {
warn 'main', 'smtp'
additivity = true
}
}
}
Staging, stg
Это тестовый сервер с железом, конфигурацией и данными максимально приближёнными к production.
Обычно данные берутся скриптом с реального сервера, и только персональная информация (пароли, email) перетираются тестовыми в целях безопасности.
На staging проводят нагрузочное тестирование и проверяются что реальные данные не поломают приложение. Например может оказатся что у вас в реальной БД есть пользователь с именем длинней чем размер поля в новой версии БД.
QA
Сборка программы для QA инженеров (тестировщиков).
Не путать с test environment — то для автоматических тестов. Автотесты не могут поймать все дефекты, особенно связанные с внешним видом.
Тут можно выделить два случая QA…
QA dev
Обычно собирается автоматически каждую ночь (или после обеда), после чего тестировщики проверяют выполненные вчера программистом задачи.
QA release
За пару недель перед релизом новая разработка замораживается (code freeze) или уже ведётся в других ветках кода для следующего релиза.
За это время тестировщики делают регрессионное тестирование где проверяют что старый функционал работает как и прежде и ничего не поломалось.
HEAD
Continuous Integration, CI — это сервер который автоматически собирает ваш проект после каждого изменения кода (pull). HEAD — это последняя версия кода, т.е.
head environment это версия приложения максимально соответствующая последнему состоянию кода.
Зачем это нужно? Ну если у вас в команде несколько человек то бывает удобно когда есть общий доступный сервер на котором быстренько можно что-то глянуть.
Т.е. похоже на QA но обновляется чаще и имеет право содержать ошибки.
Demo, Acceptance
Демо версия для сдачи итерации заказчику. Этот сервер должен быть доступен заказчику из интернета.
Всё должно быть сделано так чтобы не произошло «демо эффекта» когда ты показываешь заказчику новый функционал и вдруг он выдаёт ошибку.
Поэтому БД всегда создаётся новая. Презентационные данные должны быть красивыми и заранее оттестированными и отрепетированными.
Известные баги нужно обходить стороной. Заказчику главное увидеть как оно работает, а то что там ещё есть баги это не так важно. Важными они станут только в ветке QA release.
Это самые базовые случаи разных сред и конфигураций которые я видел. Разумеется их может быть больше. На это влияет структура проекта, процесс разработки и особенности серверов.
А вообще это вроде как относится к понятию Configuration Managment, но как я вижу на практике этим термином просто называют инструменты Chef и Puppet которые хранят конфигурацию как код.
Буду рад услышать если вы можете дополнить эту информацию или подскажете где можно почитать.
Расскажите как у вас настроено на проекте 🙂 Спасибо.
UPD Также почитайте мой совет Избегайте использования Environment вне файлов конфигураций
